Glue code analysis in open-source projects that use BDD tools
Idea
There are a lot of Behavior Driven Development (BDD) tools available in practice. To involve non-technical stakeholders in specifying requirements, these tools encourage writing behavior specifications as constrained natural text. Some of them allow specification as plain text (for example in Given...When...Then format, i.e., using Gherkin syntax).
 |
It is then connected through a glue code (i.e., test cases) to the underlying implementation.
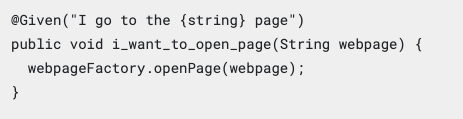 |
On the other hand, few BDD tools allow specification as a code with added annotations in order to reduce re-writing of natural language specifications.
 |
The glue code serves as a bridge from higher-level specification to the implementation level details. The characteristics of such glue code and annotations are not yet studied. It is also not clear how much glue code is auto-generated and how much must be written manually. We have collected a list of open-source projects that use one of the several BDD tools, i.e., Cucumber. You can find the data collection pipeline in this repo (we used Jupyter notebook to fetch GitHub projects). These projects, in particular, the .feature files and glue code files, can be studied to understand the characteristics of the glue code. It is crucial to find out why does the current BDD approach that involves glue code leads to a vast number of specifications that quickly become unmaintainable.
Research questions
- What are the characteristics of glue code? We should aim to characterize the properties of glue code, such as common types of input parameters, types of operations one performs inside the glue code methods, and frequency of replication.
- What parts of specifications are automatically mapped in the autogenerated part of the glue code We should aim to explore the correlation between .feature files and glue code files to understand what information BDD frameworks automatically map from behavior specifications to automatically generated glue code.
- What parts of the manually written glue code connect to the implementation? We should aim to explore the correlation between the glue code files and corresponding source code files to understand the kind of information developers map from the glue code to the source code. For instance, in how many files must they make changes.
Tasks
- Analysis of Cucumber related projects to understand the characteristics of glue code