Sandbox for Persistence Entities and further analysis
#Summary
The main idea of the project is the evaluation of persistence layer with regard to the performance in case of accessing the database over analyzed layer. We will evaluate the approach of quality evaluation without the knowledge of layer and database structure. This can be done by extracting relevant SQL statements from the software and the underlying execution plan from the database.
We will start the analysis with the following key message
criteria = builder.createQuery(UserEntity.class);
Root root = criteria.from(UserEntity.class);
Predicate idPredicate = builder.equal(root.get("id"), id);
criteria = criteria.select(root).where(idPredicate);
TypedQuery query = getEntityManager().createQuery(criteria);
return query.getSingleResult();
}
```
This method will trigger the following execution steps
The question often raised in terms of software quality analysis, e.g. in the case of performance problems, is: **"How expensive is this method"?**
The naive approach would be to extract the resulted SQL statement from TypedQuery and then take a look at the execution plan of this query.
Unfortunately, this approach will not succeed.
The definition of the underlying Persistence Entities influences the **amount** and **structure** of resulted SQL Queries by accessing the entities. The following two Entities will trigger different amount of SQL statements
```
@Entity
@Table(name = "USERS")
public class UserEntity {
@Id
@Column(name = "ID")
private Long id;
@JoinColumn(name = "ID_USER")
@OneToMany(fetch = FetchType.EAGER)
private Set phones;
}
```
```
@Entity
@Table(name = "USERS")
public class UserEntity {
@Id
@Column(name = "ID")
private Long id;
@JoinColumn(name = "ID_USER")
@OneToMany(fetch = FetchType.LAZY)
private Set phones;
}
```
The difference between these two definitions is not clear straight away. It is one single line, which is different in the code
```
@OneToMany(fetch = FetchType.EAGER) != @OneToMany(fetch = FetchType.LAZY)
```
The "EAGER" part will immediately trigger the selection of PhoneEntity and the "LAZY" part will not.
In industrial projects it is not uncommon to have hundreds of tables in the database with hundreds of definitions of Persistence Entities. These circumstances make the complete analysis of a full persistence layer extremely complicated and hard to achieve.
Even the extraction of all SQL statements, triggered by the analyzed method, will not be able to answer the question about the costs. During the software analysis insufficient attention is often paid to the structure of the underlying database. The execution plan of a database depends on availability of suitable **indices** and the **size** of the tables.
#Research Questions
**Norm and Metric**
- What is an appropriate [norm](https://en.wikipedia.org/wiki/Norm_(mathematics)) to describe the "price" of the method?
- What is an appropriate [metric](https://en.wikipedia.org/wiki/Metric_(mathematics)) to compare two methods?
**Analysis**
- How to undertake the analysis?
#Project Idea
The main idea is to write a system that accepts a persistence entity and returns a cost value of predefined execution methods, e.g. accessing the entity by id. This can be done by designing a sanbox that
- accepts the entity
- injects this entity into predefined piece of the software
- executes a predefined set of operations (only *"select"* statements for data safety reasons)
- returns the calculated cost for every executed method
The information exchange medium should be a [message broker](https://en.wikipedia.org/wiki/Message_broker) to perform distributed and scalable calculation.
Furthermore, the system must be able to support 2..n [JPA](https://en.wikipedia.org/wiki/Java_Persistence_API) implementations and 2..n Database Systems in order to analyze every industrial implementation.
For our analysis we define the following options:
**JPA**
- [Hibernate](https://en.wikipedia.org/wiki/Hibernate_(framework))
- [Eclipse Link](https://en.wikipedia.org/wiki/EclipseLink)
**DBMS**
- [Oracle](https://en.wikipedia.org/wiki/Oracle_Database)
- [PostgreSQL](https://en.wikipedia.org/wiki/PostgreSQL)

#Scope
Construction of sandbox can be done together with a supervisor of the project. The level of student's involvement in the process of sandbox definition can vary from 0% to 100%
#Implementation Hints
- Asynchronous processing is more appropriate for high performance systems
- [Active MQ](http://activemq.apache.org) is a very nice and lightweight open source message broker
- Java is not a [scripting language](https://en.wikipedia.org/wiki/Scripting_language). Compiling is needed after injection
- In the industrial environment Oracle is often used as RDBMS. Therefore, we should support this product.
#Contact
[Kirill Levitin](https://scg.unibe.ch/wiki/alumni/kirill)
**The modern software is too complex for the complete analysis. Take it as a "black box" and extract only the results from this "black box**"
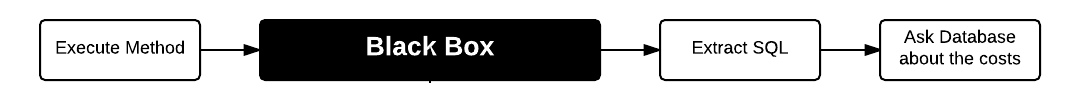
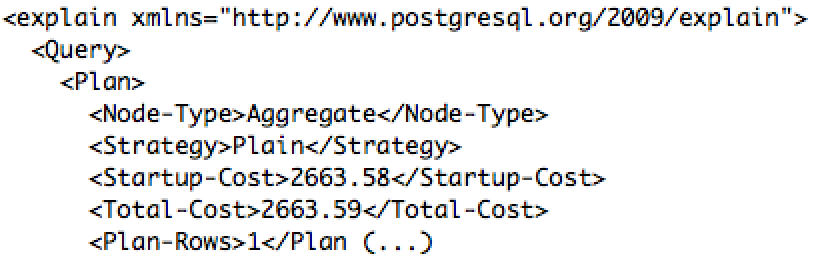
**Example of EXPLAIN in PostgreSQL**
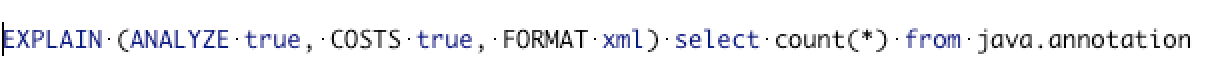
#Motivation
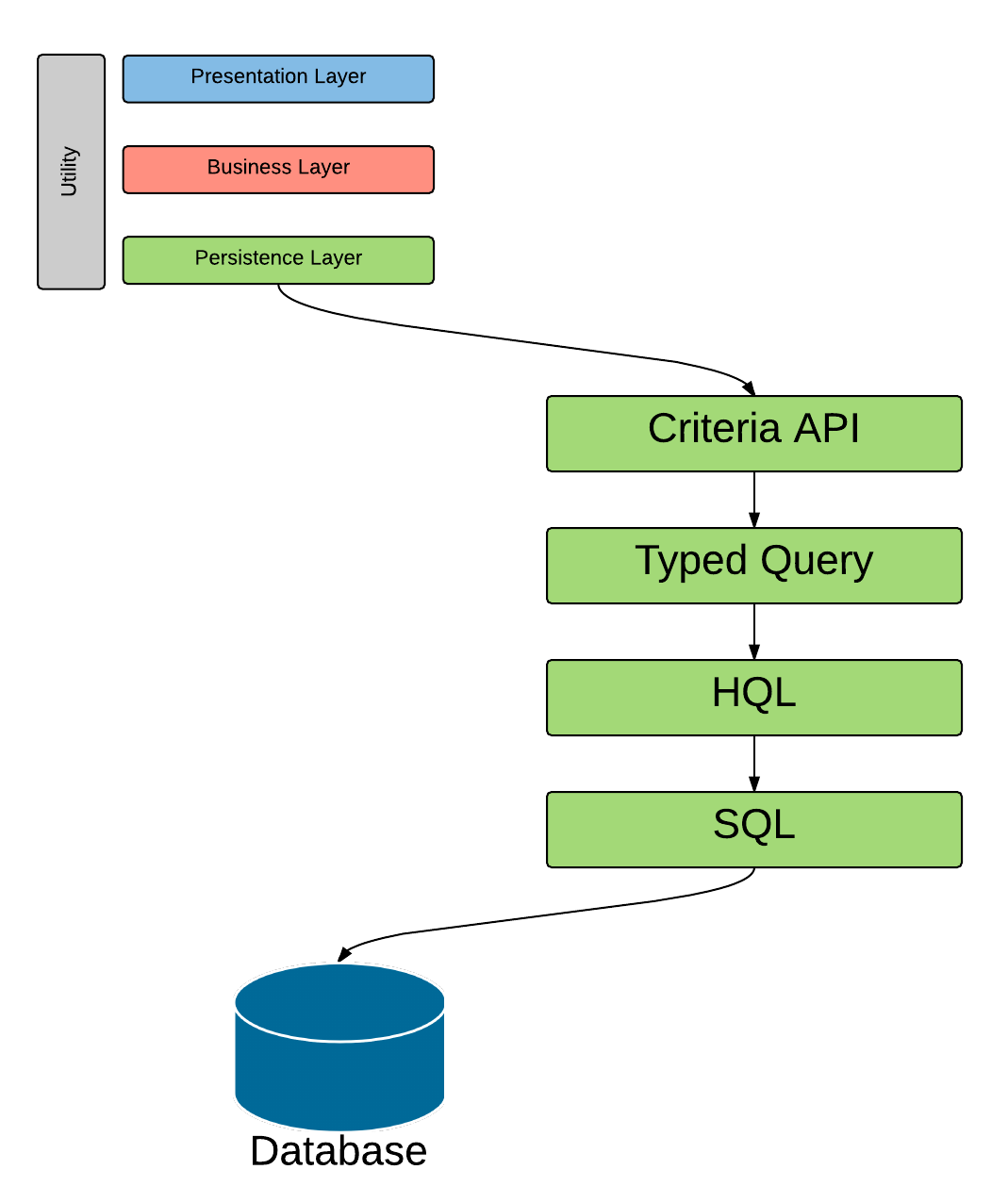
When looking at a typical enterprise software layering, the following four layers are often given as an example
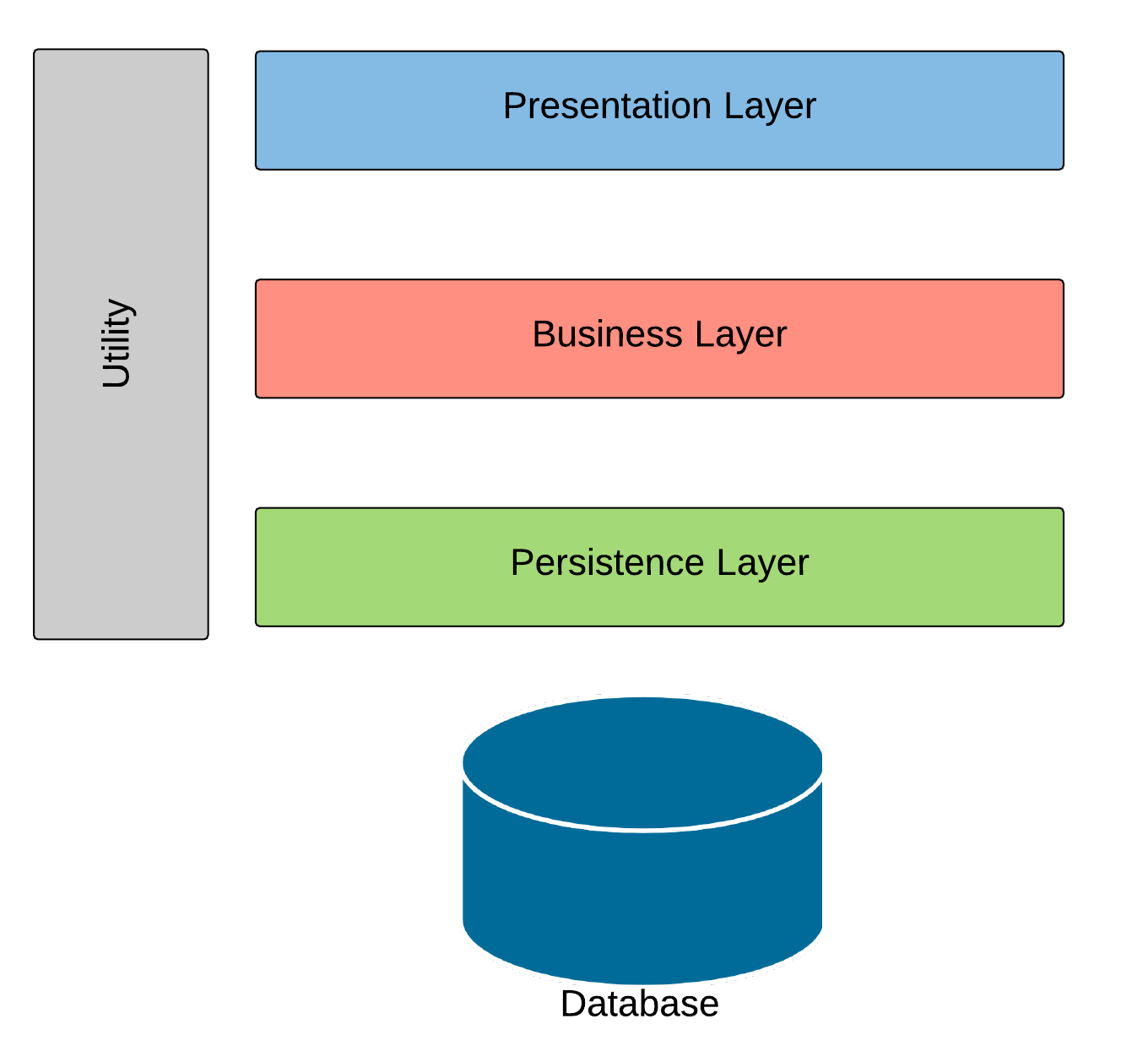
This overview does not mention the transition from persistence layer to the underlying data in the database. Lets take a look at a simple example using Criteria API.
```
public UserEntity findById(Long id) {
CriteriaBuilder builder = getEntityManager().getCriteriaBuilder();
CriteriaQuery