Inferring NoSQL Database Schemas
RQ: To what extent is it possible to infer the implicit schema of a NoSQL database?
Motivation:
No SQL databases are popular because they do not imnpose a rigid schema on the data they store. A usuable database always has an implicit, underlyingg schema, however. Consider a contacts database, a bibliographic database, or even a shopping list, contains records that mostly have the same fields, or variants of them, and those fields contain values of similar or comparable types.
Given such a textual database, we would like to parse it, build up the database structures, analyze it, identify meaningful clusters of similar records, and infer the schema and the types of semantically meaningful entities. For example, in a bibliohgraphic databases, we expect books to have similar properties, which will be different from articles or trheses. In a contacts database, we expect different sets of fields for people and companies.
Approach:
The project could focus any of a number of different aspects: building up case studies (i.e., parsing and model construction), clustering of similar entities, analysis of field types, or even visualization.
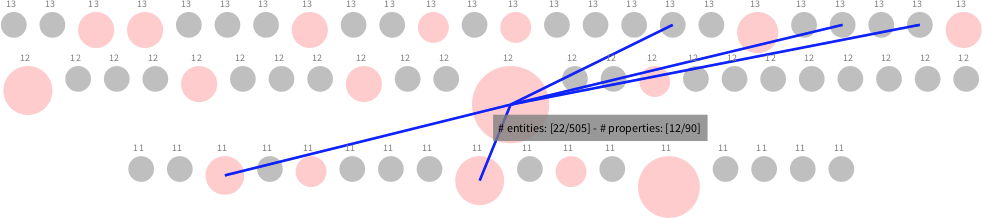 The figure visualizes SCG publications, partially ordered by their properties. Bigger nodes contain more papers with the same kinds of attributes. The selected node contains publications with the same peoperties, which all turn out to be theses.
The figure visualizes SCG publications, partially ordered by their properties. Bigger nodes contain more papers with the same kinds of attributes. The selected node contains publications with the same peoperties, which all turn out to be theses.
Contact!